

- Основні означення
- 9.2 Властивості розподілених баз даних
- 9.3 Логічна архітектура розподілених баз даних
- 9.4 Архітектура програмно-технічних засобів розподілених СКБД
- 9.4 Розподілене зберігання даних
- 9.5 Обробка розподілених транзакцій
Ключові терміни:
видавць, дистриб’ютор, передплатник, реплікація, розподілена база даних, розподілена система баз даних, розподілена система керування базами даних, транзакція, фрагментаціяОсновні означення
Розподілена база даних (РБД) ‒ це множина логічно взаємозалежних баз даних, розподілених у комп’ютерній мережі.
Розподілена система керування базами даних (РСКБД) ‒ це програмне забезпечення, яке керує РБД і надає такі механізми доступу до них, що їх застосування дає користувачу можливість працювати з РБД як з однією цілісною базою даних.
Розподілена система баз даних (РСБД) ‒ це РБД разом із РСКБД.
Не слід плутати РСБД з централізованою базою даних, що використовується в мережі (рис. 9.1). У цьому випадку база даних розташована на одному з комп’ютерів, а всі інші мають доступ до неї через комунікаційну мережу. Не є розподіленою також база даних, що працює в середовищі багатопроцесорних комп’ютерів. У цьому випадку ми маємо справу з паралельною БД.
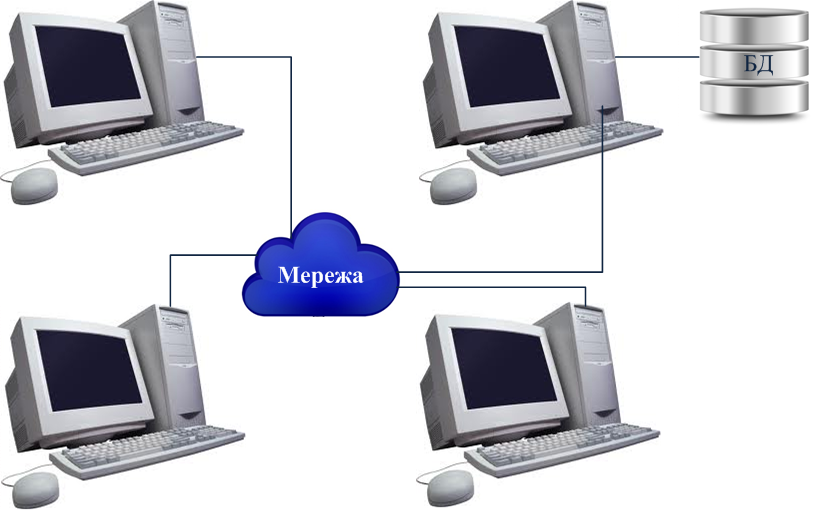
Рисунок 9.1 ‒ Централізована база даних у комп’ютерній мережі
Архітектура розподіленої СКБД наведена на рис. 9.2. Кожний з вузлів мережі містить свою базу даних, однак вони розглядаються як логічно єдина база, а не як сукупність розкиданих у мережі файлів. Усі дані є логічно взаємозалежними. Розподілена СКБД — це повноцінна СКБД, що виконує всі необхідні функції з керування даними.
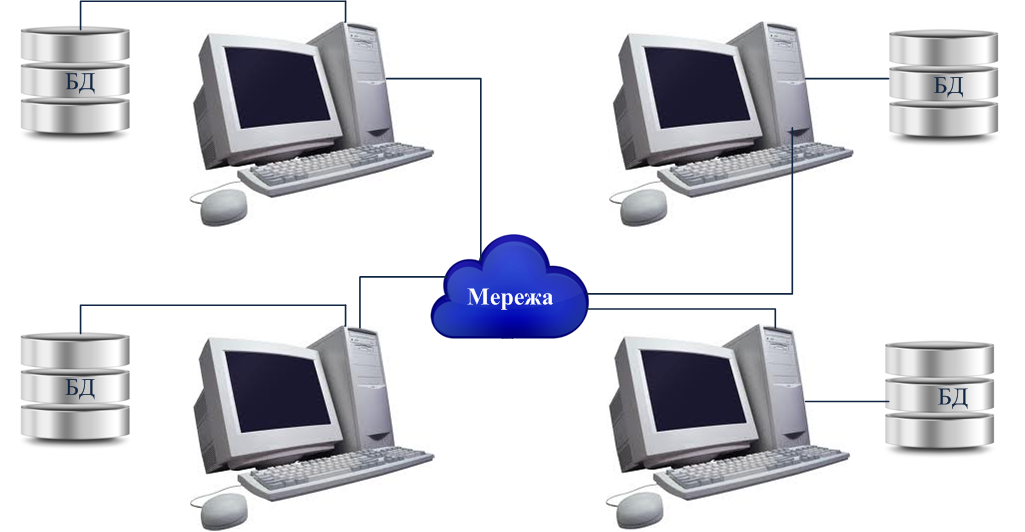
Рисунок 9.2 - Розподілена база даних
Залежно від типу програмного забезпечення розрізняють два типи РСКБД:
- однорідні;
- неоднорідні.
В однорідних РСКБД передбачається, як мінімум, що на всіх вузлах використовуються однотипні СКБД (наприклад, реляційні), які мають схожі функціональні можливості. Як максимум, припускається, що на всіх вузлах використовуються однакові технічні засоби, тобто однакові типи комп’ютерів і програмного забезпечення. Це стосується операційних систем, програмного забезпечення СКБД та моделей даних, що підтримуються.
У неоднорідних РСКБД вузли базуються на різних програмно-технічних платформах, які можуть містити різні типи СКБД. Окрім того, такі СКБД можуть підтримувати різні моделі даних. У цьому випадку ускладнюється вирішення проблеми їхньої взаємодії.
Однією з важливих проблем РСКБД є досягнення логічної незалежності даних від місця зберігання, тобто прозорість доступу до даних. Це означає, що користувач повинен мати можливість сприймати всі необхідні йому дані як єдине ціле, не зважаючи на те, в який спосіб вони розподілені у мережі.
9.2 Властивості розподілених баз даних
Вперше завдання про дослідження основ і принципів створення і функціонування розподілених інформаційних систем було поставлене відомим фахівцем в області баз даних Д. Дейтом.
Локальна автономія (local autonomy). Ця якість означає, що управління даними на кожному з вузлів розподіленої системи виконується локально. База даних, розташована на одному з вузлів, є невід'ємним компонентом розподіленої системи. Будучи фрагментом загального простору даних, вона в той же час функціонує як повноцінна локальна база даних, а управління нею здійснюється локально, незалежно від інших вузлів системи.
Незалежність вузлів (no reliance on central site). Всі вузли рівноправні і незалежні, а розташовані на них БД є рівноправними постачальниками даних в загальний простір даних. База даних на кожному з вузлів самодостатньою — вона включає повний власний словник даних і повністю захищена від несанкціонованого доступу.
Безперервні операції (continuous operation). Це можливість безперервного доступу до даних в рамках розподіленої БД незалежно від їх розташування і незалежно від операцій, що виконуються на локальних вузлах.
Прозорість розташування (location independence). Користувач, що звертається до БД, нічого не повинен знати про реальне, фізичне розміщення даних у вузлах інформаційної системи.
Прозора фрагментація (fragmentation independence). Можливість розподіленого (тобто на різних вузлах) розміщення даних, логічно поєднаних в єдине ціле. Існує фрагментація двох типів: горизонтальна і вертикальна. Перша означає, що рядки таблиці зберігаються на різних вузлах. Друга означає розподіл стовпців логічної таблиці по декількох вузлах.
Прозоре тиражування (replication independence). Тиражування даних - це асинхронний процес перенесення змін об'єктів вихідної бази даних в бази, розташовані на інших вузлах розподіленої системи
Обробка розподілених запитів (distributed query processing). Можливість виконання операцій вибірки даних з розподіленої БД, за допомогою запитів, сформульованих на мові SQL
Обробка розподілених транзакцій (distributed transaction processing). Можливість виконання операцій оновлення розподіленої бази даних, які не порушують цілісність і узгодженість даних. Ця мета досягається вживанням двофазного протоколу фіксації транзакцій.
Незалежність від устаткування (hardware independence). Ця властивість означає, що як вузли розподіленої системи можуть виступати ПК будь-яких моделей і виробників
Незалежність від операційних систем (operationg system independence). Ця якість витікає з попереднього і означає різноманіття операційних систем, керуючих вузлами розподіленої системи
Прозорість мережі (network independence). Доступ до будь-яких баз даних відбувається по мережі. Спектр підтримуваних конкретною СУБД мережевих протоколів не має бути обмеженням системи, заснованої на розподіленій БД
Незалежність від баз даних (database independence). Ця якість означає, що в розподіленій системі можуть працювати СУБД різних виробників, і можливі операції пошуку і оновлення в базах даних різних моделей і форматів.
9.3 Логічна архітектура розподілених баз даних
Логічна архітектура розподілених баз даних ‒ це архітектура логічно взаємозалежних даних. Графічне зображення логічної архітектури розподілених баз даних наведене на рис. 9.3. Особливість архітектури РБД полягає в тому, що виникає ще один рівень, глобальний концептуальний, завданням якого (як і в моделі ANSI/SPARC) є зображення концептуальної моделі предметної області в цілому. На цьому рівні описується характер розподілу даних.
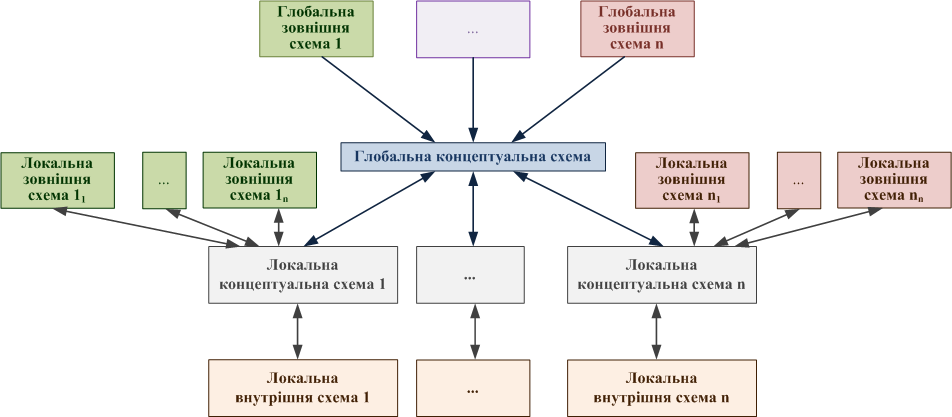
Рисунок 9.3 ‒ Логічна архітектура розподіленої СКБД
На локальному концептуальному рівні здійснюється локальний опис ПО. Тобто схема цього рівня містить опис тільки тієї частини предметної області, що є специфічною для конкретного вузла розподіленої ПО; дані інших вузлів розподіленої ПО в схемі не вказуються. Відображення «глобальний-концептуальний/локальний-концептуальний» дають змогу зобразити глобальну концептуальну схему у вигляді сукупності локальних концептуальних схем, і навпаки.
Глобальна зовнішня схема зображує дані, необхідні користувачам і додаткам, у бажаному для них вигляді, незалежно від способу розподілу даних за вузлами. Це завдання вирішується завдяки тому, що глобальні зовнішні схеми базуються на глобальній концептуальній схемі.
Локальні зовнішні схеми базуються на локальних концептуальних схемах, відтак вони можуть посилатися лише на ті дані, що розташовані на відповідному вузлі розподіленої ПО.
Локальні внутрішні схеми ‒ це схеми зберігання даних на конкретних вузлах розподіленої ПО. Вони пов’язані з відповідними локальними концептуальними схемами.
9.4 Архітектура програмно-технічних засобів розподілених СКБД
9.4.1. Властивості архітектури
Архітектура програмно-технічного комплексу розподілених СКБД має три головні характеристики:
- розподіленість;
- неоднорідність;
- автономність.
Розподіленість. Спосіб розподілу компонентів системи баз даних за комп’ютерами мережі визначається тим, чи є в мережі єдиний комп’ютер з повноваженнями розподіленої СКБД, або ж їх кілька. Якщо таких комп’ютерів кілька, то чи є між ними взаємодія тощо.
Неоднорідність. Важливою характеристикою є міра однорідності програмно-технічних засобів СКБД. Ідеться про технічне забезпечення (типи комп’ютерів), комунікаційні засоби зв’язку, операційні системи і типи баз даних (моделі даних, мови запитів, алгоритми керування транзакціями тощо).
Автономність. Характеризує, наскільки самостійно компоненти СКБД можуть виконувати свої функції. До питань автономності належать:
- автономність проектних рішень (наскільки самостійно компоненти СКБД можуть розв’язувати задачі, які були спроектовані для них); автономність вирішенням комунікаційних проблем (наскільки самостійно компоненти СКБД можуть встановлювати зв’язки з іншими компонентами);
- автономність обчислень (наскільки самостійно компоненти СКБД можуть приймати рішення щодо виконання локальних операцій).
9.3.2. Різновиди архітектури
Основними різновидами архітектури програмно-технічних засобів розподіленої СКБД є:
- клієнт-серверна архітектура;
- архітектура з багатьма незалежними серверами;
- архітектура із взаємодіючими серверами;
- архітектура однорангової мережі.
Клієнт-серверна архітектура. Така архітектура передбачає наявність єдиного комп’ютера-сервера і багатьох комп’ютерів-клієнтів, що взаємодіють між собою через канали зв’язку. На сервері розташована СКБД та інтегрована (централізована) база даних. Ніякого розподілу баз даних за вузлами мережі немає. На клієнтських комп’ютерах виконуються додатки, які працюють із серверною базою даних, а також розміщене програмне забезпечення для зв’язку з віддаленою СКБД. Як клієнти, так і сервер оснащені комунікаційним програмним забезпеченням.
Архітектура з багатьма незалежними серверами. Ця архітектура передбачає існування багатьох серверів, що мають доступ до своїх локальних баз даних. У такому випадку на комп’ютерах клієнтів має зберігатись інформація стосовно того, які дані на яких серверах розташовані, а також має бути розміщене програмне забезпечення, що дає змогу декомпозувати запити для їхнього виконання на різних серверах і потім об’єднати результати.
Архітектура із взаємодіючими серверами. У цьому випадку передбачається, що кожний із серверів містить повну інформацію стосовно того, які дані на яких серверах зберігаються, а також здатний обробляти розподілені запити. У разі потреби один сервер може звернутися до іншого для одержання необхідних даних. Кожен клієнт має свій сервер, до якого звертається для виконання операцій над розподіленою базою даних.
Архітектура однорангової мережі. Усі комп’ютери мережі є серверами. На кожному комп’ютері розміщено розподілену СКБД і базу даних, з кожного комп’ютера можна надіслати до іншого запит на отримання необхідних даних.
9.4 Розподілене зберігання даних
У розподіленій СКБД дані розподіляються за вузлами мережі. Існують два основні механізми розподіленого зберігання даних:
- фрагментація;
- реплікація
9.4.1. Фрагментація
Суть фрагментації полягає в тому, щоб поділити логічну базу даних на фрагменти з метою зберігання кожного фрагмента на певному вузлі мережі. Одиницями фрагментації можуть бути відношення та складені відношення. У випадку, коли одиницею фрагментації є відношення, вирішується проблема, яке відношення в якій базі даних має зберігатися. За іншого підходу допускається, що будь-яке відношення може бути зображене у вигляді сукупності фрагментів, що розподіляються за різними базами даних.
Фрагментацію, що здійснюється розподілом відношень за базами даних, теоретично здійснити нескладно, тому розглянемо проблему фрагментації власне відношень.
Фрагментація відношень. Завдання фрагментації відношень формулюється в такий спосіб. Нехай задане відношення R. Його потрібно зобразити у вигляді сукупності відношень R1, ..., Rn так, щоб ця сукупність відповідала критеріям ефективності (за часом доступу, пам’яттю, завантаженістю комп’ютерів тощо).
Фрагментація є коректною, якщо вона повна, не містить перетинів і може бути реконструйована. Пояснимо ці терміни.
Декомпозиція відношення R на фрагменти R1, R2, … Rn є повною тоді й лише тоді, коли кожен елемент даних з R належить якомусь із відношень Ri.
Декомпозиція відношення R на фрагменти R1, R2, … Rn може бути реконструйована, якщо існує такий реляційний вираз φ(R1, R2, … Rn), що R=φ(R1, R2, … Rn).
Декомпозиція відношення R на фрагменти R1, R2, … Rn не містіть перетинів, якщо будь-який елемент даних з R міститься не більш ніж в одному фрагменті.
Є три типи фрагментації відношень:
- горизонтальна;
- вертикальна;
- змішана
Горизонтальна фрагментація
Горизонтальна фрагментація полягає в розподілі кортежів відношення за фрагментами. Формально горизонтальну фрагментацію можна визначити в такий спосіб. Нехай задане відношення R і на ньому визначений предикат Fi. Тоді горизонтальний фрагмент Rі відношення визначається так:
[TEX]R_{i} =\sigma _{F_{i} }(R)[/TEX]
Тобто горизонтальний фрагмент Rі - це множина кортежів R, що задовольняють умову Fi.
Нехай задане відношення
ПРОЕКТ (Рном, Назва, Тип, Вартість).
Очевидно, що множина предикатів
{ Вартість < 300000. Вартість = 300000. Вартість > 300000}
породжує повну фрагментацію відношення ПРОЕКТ, яка не містить перетинів. Предикати
{ Вартість < 300000. Вартість > 200000}
породжують повну фрагментацію, що містить перетин. А предикати
{ Вартість < 200. Вартість > 300}
породжують неповну фрагментацію, яка не містить перетинів.
Переваги горизонтальної фрагментації:
- дає змогу паралельно обробляти фрагменти відношення;
- дає можливість поділяти відношення так, щоб кортежі розташовувалися там, де вони будуть використовуватися найчастіше.
Вертикальна фрагментація
Суть вертикальної фрагментації полягає в тому, що відношення поділяється на дві чи більше проекцій, тобто схема відношення поділяється на певну множину підсхем.
Для відновлення вихідного відношення з фрагментів необхідно, щоб усі підсхеми містили первинний ключ. Існує інший підхід, коли під час поділу схеми до кожного фрагмента автоматично додається поле з ідентифікатором кортежу. Значення цього ідентифікатора зазвичай встановлюються системою автоматично.
Нехай задано відношення
ПОСТАЧАННЯ(#Рном, Постачальник, Обладнання, Проект).
ПОСТАЧАННЯ
|
#Рном |
Постачальник |
Обладнання |
Проект |
|
Р1 |
Іванов |
Двигун |
АН-24 |
|
Р2 |
Іванов |
Двигун |
ЯК-40 |
|
РЗ |
Іванов |
Шасі |
АН-24 |
|
Р4 |
Петров |
Двигун |
АН-24 |
|
Р5 |
Петров |
Електрообладнання |
ЯК-40 |
|
Р6 |
Петров |
Електрообладнання |
АН-70 |
Вертикальна фрагментація з використанням первинного ключа може виглядати так:
ПОСТАЧАННЯ-1
|
#Рном |
Обладнання |
Проект |
|
Р1 |
Двигун |
АН-24 |
|
Р2 |
Двигун |
ЯК-40 |
|
РЗ |
Шасі |
АН-24 |
|
Р4 |
Двигун |
АН-24 |
|
Р5 |
Електрообладнання |
ЯК-40 |
|
Р6 |
Електрообладнання |
АН-70 |
ПОСТАЧАННЯ-2
|
#Рном |
Постачальник |
|
Р1 |
Іванов |
|
Р2 |
Іванов |
|
РЗ |
Іванов |
|
Р4 |
Петров |
|
Р5 |
Петров |
|
Р6 |
Петров |
Переваги вертикальної фрагментації:
- дає змогу поділяти кортежі відношення так, щоб їхні частини розташовувалися там, де вони використовуватимуться найчастіше;
- дає змогу проводити паралельну обробку відношень;
- наявність ідентифікатора кортежу дає можливість здійснювати ефективне з’єднання вертикальних фрагментів.
Змішана фрагментація. Змішана фрагментація передбачає послідовне застосування вертикальної і горизонтальної фрагментацій.
Розподіл даних за вузлами мережі
Після отримання усіх необхідних фрагментів відношень постає проблема розподілу цих фрагментів за вузлами мережі. Єдиних рекомендацій стосовно того, як це робити, немає. Потрібно знайти оптимальний розподіл фрагментів F за вузлами мережі S за умови, що відомий розподіл додатків Q за вузлами мережі.
Визначаючи оптимальність, слід враховувати різні параметри, зокрема:
- вартість передавання, зберігання й обробки даних;
- часові характеристики;
- продуктивність;
- обмеження (наприклад, ємнісні характеристики вузлів мережі).
Для того щоб розподілити фрагменти за вузлами мережі, необхідна додаткова інформація, яка стосується
- бази даних та розмірів фрагментів;
- додатків (місць їхнього розташування, частоти використання тих чи інших фрагментів для вибирання даних, частоти використання фрагментів для відновлення даних);
- вузлів мережі (вартості зберігання й обробки даних у вузлах);
- мережі (вартості та часових характеристик передавання даних між двома вузлами).
9.4.2. Реплікація
Реплікація — це механізм розподілу даних за вузлами, що дозволяє зберігати копії тих самих даних на різних вузлах мережі з метою прискорення пошуку і підвищення стійкості до відмов. Відношення чи фрагмент є реплікованим, якщо його копії зберігаються на двох або більше вузлах (копії ще називають репліками). За повної реплікації відношення його копії зберігаються на всіх вузлах мережі. Допускається ситуація, коли вся база даних зберігається на всіх вузлах мережі — це називається поєною реплікацією бази даних.
Переваги реплікації:
- доступність (у разі перебою в роботі вузла, що містить відношення Н, його доступність на інших вузлах зберігається);
- паралелізм (виконання запитів до відношення R може бути розпаралелено за всіма репліками відношення);
- зниження вартості передавання даних (відношення R доступне локально в усіх вузлах, де є його репліки).
Недоліки реплікації:
- підвищується вартість зберігання, створення і відновлення даних; підвищуються вимоги до ресурсів;
- ускладнюється підтримання цілісності даних, наприклад одночасне відновлення різних реплік одного й того ж відношення
Механізми реплікації
Для реалізації реплікації використовуються три сервери: видавець, дистриб’ютор і передплатник.
Видавцем називають сервер, що надає розміщені на ньому дані для копіювання на інші сервери. Окрім створення копії даних, видавець відстежує внесені до його бази даних зміни і готує нову копію.
Дистриб’ютором називається сервер, що підтримує розподілену базу даних. Він виконує роль посередника, копіює всі публікації, підготовлені видавцем, і пересилає їх передплатникам. Дистриб’ютором може бути виділений сервер або сервер, сконфігурований як видавець чи передплатник. Конкретні функції, що їх виконує дистриб’ютор, залежать від методів реплікації.
Передплатником називається сервер, що отримує копії даних, надані видавцем. Механізми зміни даних передплатником відрізняються від механізмів зміни даних видавцем.
Є два методи відновлення даних передплатників:
- Реплікація за запитом. Передплатник періодично звертається до дистриб’ютора із запитом про зміни, що відбулися з моменту останнього з’єднання.
- Примусова реплікація. Дистриб’ютор сам встановлює з’єднання з передплатником і пересилає йому необхідні дані.
Залежно від методу реплікації, передплатники можуть чи не можуть вносити зміни в репліковані дані. У найпростішому випадку змінювати дані може тільки видавець, у складніших моделях реплікації - передплатники і видавці. Змінені дані, отримані від усіх передплатників, синхронізуються і поєднуються з даними видавця, а потім розсилаються передплатникам.
Моделі реплікації
Є такі моделі реплікації:
- реплікація моментальних знімків;
- реплікація транзакцій.
Реплікація моментальних знімків є найпростішою моделлю реплікації. Моментальний знімок це повна копія даних, обраних для реплікації; вона розсилається передплатникам.
Під час реплікації транзакцій використовується журнал транзакцій бази даних. Обрані транзакції копіюються в базу даних дистриб’ютора зі збереженням інформації про послідовність їхнього виконання, потім розсилаються серверам- передплатникам і виконуються на них у тому ж порядку, в якому виконувалися на сервері-видавці.
Цей механізм зменшує завантаження мережі, його рекомендується використовувати у великих базах даних з невеликою кількістю змін.
Топологія реплікацій
Топологія реплікацій описує характер взаємозв’язків між учасниками реплікації:
- реплікація «один-до-багатьох» передбачає наявність одного видавця і кількох передплатників;
- реплікація «багато-до-одного» має місце, коли дані від кількох видавців пересилаються одному передплатнику;
- реплікація «багато-до-багатьох» означає, що дані від кількох видавців пересилаються кільком передплатникам.
9.5 Обробка розподілених транзакцій
Транзакція — набір команд, що виконується як єдине ціле. У транзакції або всі команди будуть виконані, або жодна з них не виконається. Якщо хоча б одна з команд транзакції не може бути виконана, здійснюється відкочування (відновлюється стан системи, в якому вона перебувала до початку виконання транзакції).
Транзакції мають задовольняти вимоги ACID (Atomicity, Consistency, Isolation, Durability — атомарність, несуперечність, ізольованість, довговічність), що гарантують правильність і надійність роботи системи.
Атомарність передбачає таке:
- виконуються всі операції транзакції або жодна з них не виконується;
- якщо виконання транзакції було перерване, то всі зроблені транзакцією зміни мають бути скасовані
Дії, спрямовані на підтримку атомарності транзакції під час її аварійного завершення у зв’язку з помилками введення/виведення, перевантаженнями системи чи блокуваннями, називаються відновленням транзакції.
Дії, спрямовані на забезпечення атомарності під час виходу з ладу системи, називаються відновленням у разі виникнення перебоїв.
Несуперечність означає, що транзакція, яка працює з несуперечною базою даних, після завершення роботи залишає її також у несуперечному стані. Транзакція не повинна порушувати цілісності бази даних
Для вирішення проблем одночасного доступу інститут ANSI розробив спеціальний стандарт, який визначає чотири рівні блокування (кожний вищий рівень передбачає виконання умов усіх нижчих рівнів)
- Рівень 0. Заборона «забруднення» даних. На цьому рівні вимагається, щоб змінювати дані могла лише одна транзакція. Якщо іншій транзакції необхідно змінити ці ж дані, то вона має очікувати завершення першої транзакції.
- Рівень 1. Заборона некоректного зчитування. Якщо певна транзакція розпочала змінювати дані, то жодна інша транзакція не зможе зчитати ці дані доти, доки перша не завершиться.
- Рівень 2. Заборона неповторюваного зчитування. Якщо певна транзакція зчитує дані, то жодна інша транзакція не зможе їх змінити. Отже, під час повторного зчитування дані перебуватимуть у початковому стані.
- Рівень 3. Заборона «фантомів». Якщо транзакція звертається до даних, то жодна інша транзакція не зможе додати чи видалити рядки, що можуть бути зчитані під час виконання транзакції. Реалізація цього рівня блокування виконується блокуванням діапазону ключів. Це блокування накладається не на конкретні рядки таблиці, а на рядки, що відповідають певній логічній умові.
Властивість ізольованості означає, що на роботу транзакції не мають впливати інші транзакції. Транзакція «бачить» дані в тому стані, в якому вони перебували до початку роботи іншої транзакції, або в тому стані, в якому вони перебувають після її завершення. Одна транзакція не може переглядати проміжні стани даних, що використовуються іншими транзакціями. Якщо транзакція зчитує кілька разів ті самі дані, то вона повинна отримувати їх щоразу в тому стані, в якому вони були під час першого зчитування. Ще одним аспектом ізольованості є неможливість роботи з неповними результатами — незавершена транзакція не може передавати свої результати іншим транзакціям до підтвердження свого успішного завершення.
Після того, як було підтверджено успішне завершення роботи транзакції (Commit), система має гарантувати, що її результати не будуть втрачені, незважаючи на можливі перебої. Це й називається довговічністю. Для забезпечення довговічності застосовуються механізми відновлення бази даних.

